这是在今天5月份的时候由Cure53的成员Masato kinugawa在第十一届的Shibuya.XSS发表的【用JavaScript实施DoS攻击】的PPT的翻译。开发者和安全行业从业者都可以参考一下。
原文链接:https://speakerdeck.com/masatokinugawa/shibuya-dot-xss-techtalk-number-11 (日文)
0x00 概要
本文将通过几个案例讲解如何利用开发者的一些小错误,来挖掘一些可以用来进行Client Side DoS 又或者是 Server Side DoS的漏洞。
0x01 实例1 URL编解码
日本某公司的产品中存在引入视频链接的功能。当我们在在引入视频功能中添加如下链接并留言时,此页面将变成即没办法浏览也在没办法留言的状态。(这是一个类似公共留言板的地方,所以受影响的不单是攻击者也包括所有需要和希望浏览这个页面的用户)
https://www.youtube.com/watch?v=%FF
所以到底发生了什么呢?在前端的代码中开发者试图用decodeURIComponent()来decode参数v的值,但很显然这个值是没办法被decodeURIComponent()所decode的,所以最终导致后续的前端代码也没有能被成功的执行,该页面也就不会被正常显示出来了。
> decodeURIComponent("%FF");
Uncaught URIError: URI malformed
那要怎么修复呢?你得考虑不成功的时候应该怎么处理,而不是假设你一定会成功。
try{
vParam=decodeURIComponent(vParam);
}
catch(e){
//放弃下一步操作
}
那URL解码的时候确实应该注意一下了,但是URL编码的时候呢,需不需要也注意一下呢?也是需要的。
> encodeURIComponent("\uDC00")
Uncaught URIError: URI malformed
那么问题又来了,有些看似很好学但从来不愿意自己去找的人肯定会问一个问题。凭什么会报错呢,我想知道原因。想知道吧?很好学吧?你可以自己去读ECMAScript的SPEC。上边都有写。
0x02 实例2 前端过滤用户输入
在前端如果用户输入会被输出到script标签内某个变量的值时,我们经常会去做这样的处理来防止XSS。
- 把
/替换成\/ - 把
"替换成\" - 把
\替换成\\
这个时候我们就可以利用换行0x0A,0x0D,0x2028,0x2029来引发JS错误,如果这个时候也和第一个例子一样没有做适当的处理,就会引发JS错误。如果后续执行的JS代码是显示该输入,那么自然也就没有办法执行。很有可能就会导致页面显示不完整或者什么都不显示。关于0x2028,0x2029的部分,在较新的浏览器中已经不会再报错了,所以可能没办法引起JS错误,但需要留意的是在IE上依旧会报错。
同样的,作为攻击者如果可以在script标签内的变量的值里输出如下内容,也可以做到不让后续js代码被执行的效果。
<script>
userInput = "<!--<script>";
displayContents();
</script>
原因是,当<!--后面出现<script>时浏览器会试图去寻找该标签的结束标签,所以代码执行到这儿的时候就会挂在那儿了。在whatwg上也有说明这个属于浏览器的正常举动,但没有写到具体的原因。有人猜测说是因为在某些浏览器都还不知道script标签是个啥玩意儿的那个年代,曾为了防止script标签内的内容直接显示在用户浏览器当中
就在标准当中了加了这一项一直延续到了现在。有点像有些没有管好的subdomain容易被takeover的感觉,不过也不重要了。
讲到这儿的时候原作者突然在这儿秀了一把XSS的操作,其实放到这个位置有点牵强,但作为有责任心的翻译者我也给顺便贴上吧。
<script> x = "<%"; </script>
<img title="%></script><iframe onload=alert(1)>" />
首先说要点。这个payload需要在IE9以下或者说IE9模式以下才能触发。如果想在最新的IE11触发,可以把目标页面用iframe加载到自己其它域的页面里,在自己的页面用meta标签把IE模式调成IE9就可以了。ie模式可以通过这种方式跨域继承。为什么这个内容会出现在这个页面是因为你把%替换成!--上面的payload也是同样有效的,所以我猜是讲到这一块的时候原作者不由自主地想到了这个payload就加到了稿子里,也变相的加大了我的翻译量。。
最后作为对策,如果输出的位置即是html content又是script content也就意味着需要对两种content进行合理的escape。escape顺序随意,只要不要漏就好。最后为了解决换行的问题你可能还需要换行进行escape处理。这样其实就差不多了。如果还是不放心你可以在输入的时候根据数据类型和实际用途先对用户输入的数据和数据的类型做一次验证。最后再输出的时候在escape这样就比较保险了。
0x03 实例3 前端的数据类型验证
接下来是个共享用户密码的web应用案例。在这个应用中,如果想要共享twitter的密码就得向服务器发送类似下边的这种POST请求:
POST /save_data HTTP/1.1
...
{"sitedata":{"url":"xxx","title":{"toString":null}}}
但是当我们发送这个请求后,所有的页面都变成了空白页面,什么都不显示。到底发生了什么呢?当我们对用户输入的数据在前端进行操作时,我们不应该假设传递过来的数据类型一定会是什么,如果我们做了这种假设那么很有可能会因为数据类型不匹配导致报错。最终导致页面无法显示。比如在下面的例子当中
name = name.toUpperCase()
如果name可控,且可给name赋予类型为integer的值(如:123)那么就会报这样的错误。
Uncaught Type Error: name.toUpperCase() is not a function
实际上在这次这个案例的前端代码中并没有使用只能用于字符串的方法来对用户数据进行处理和操作。(参考下述代码)
siteData={"title":{"toString":null},...}
title="title:"+siteData.title;
那是为什么报错了呢?因为不论是toString还是valueOf都是需要在内部进行数据类型转换时才会被调用的。但是不论是哪一个都必须返回以下数据类型中的一种:
- 数字
- 字符
- 布尔
- null
- undefined
但由于此处被指定null本来就不是函数,所以根本没有办法返回上边的任何一种。所以就会报TypeError。
>>({toString:null})+"";
TypeError: can't convert object to primitive type
作为对策,可以在前端/后端做数据类型的验证。前端的话可以用下边的几种方法:
- typeof
- Array.isArray()
- Object.prototype.toString.call()
每个方法各有千秋,像第一个区分不了object,array和null。像判断是否是数组就可以用第二个方法,如果是null可以直接和null作比较,如果不想搞得这么麻烦想一次搞定就可以用最后的·Object.prototype.toString.call()来进行判断。
0x04 实例4 proto
在某聊天软件里,允许了一部分看上去没有什么危害的HTML标签。但当攻击者把下面的内容发送给受害者时,受害者的聊天功能就完全失效了。
<toString>AAA</toString>
在另外一个聊天软件里,攻击者上传扩展名为.constructor的文件之后,上传到这个聊天室的所有的附件都变得不可见了。
test.constructor
为什么呢?让我们一步一步地去讲这个问题。当我们想存储一组数据(如key和value)时经常会使用object。如果我们想写一个输入水果名称就可以告诉我们水果颜色的函数我们也许会这么写:
function fruit(input) {
fruits = {
"apple": "red",
"lemon": "yellow"
};
if (fruits[input]) {
return input + ":" + fruits[input]
} else {
return "go home kid you're drunk."
}
}
下边让我们来做一些简单的测试。当我们输入fruit("apple")返回apple:red,看上去没啥毛病。那如果我们输入fruit("toString")呢?结果会返回:
"toString:function toString() {
[native code]
}"
输入fruit("constructor")则返回:
"constructor:function Object() {
[native code]
}"
看上去有点奇怪。这两个孩子是谁的呢?在解释这个之前我们先看一下对象的访问是什么样的一个过程 。
第一步 如果对象拥有我们想访问的属性则返回,如果没有就跳到第二步
第二步 如果__proto__有这个属性则返回,没有就跳到第三步
第三步 从__proto__的__proto__再去找这个属性,如果有就返回没有就跳到第四步
以此类推。那这两个孩子是proto的没跑了。不过proto是哪儿来的呢?这个其实是被自动创建的(参考下图)

所以当我们执行fruit("constructor")时由于fruit自身没有这个属性,就会跑去查__proto__的,而proto正好有这个(参考下图)
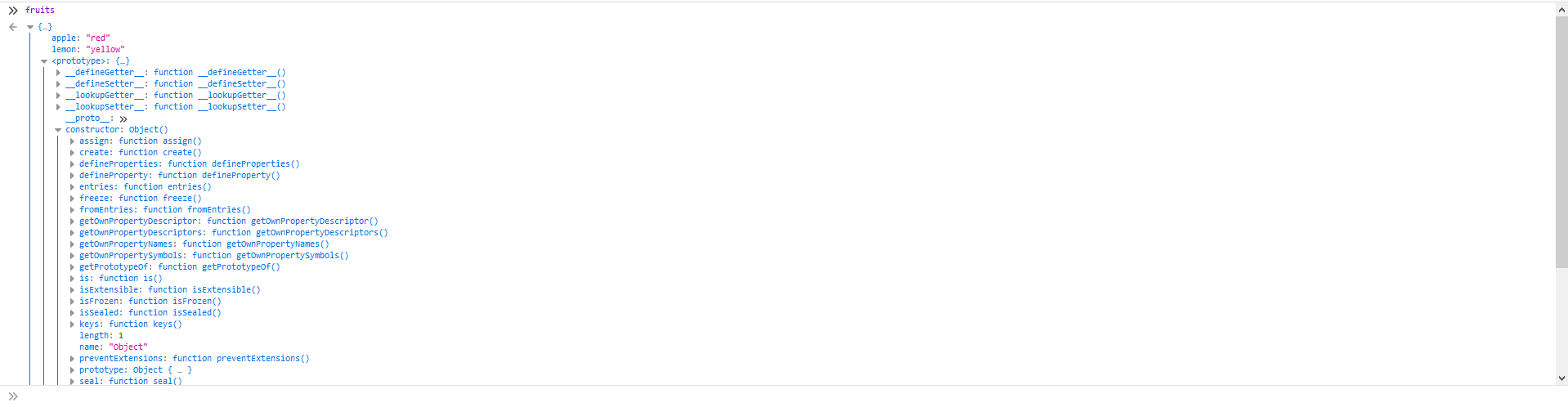
最后就会返回下边这一坨了。
"constructor:function Object() {
[native code]
}"
最终由于访问到的东西和预期的不一样,后续的处理出问题也就不奇怪了。如果你的项目中也存在类似的代码或者问题,可以通过下边这种方式进行修正。
function fruit(input) {
fruits = {
"apple": "red",
"lemon": "yellow"
};
if (Object.prototype.hasOwnProperty.call(fruits, input)) {
return input + ":" + fruits[input]
} else {
return "Go home youre drunk."
}
}
0x05 实例5 Node.js
当我们向某个用Node.js编写的应用发送如下请求时,应用直接就挂了。
PSOT /API HTTP/1.1
{"query":{"length":1e10,"constroctor":{"name":"Array"}}}
所以发生了什么呢?我们先看看后端的代码:
INPUT = {
"length": 1e10,
"constructor": {
"name": "Array"
}
};
if (INPUT.constructor.name === "Array") {
array = [];
for (var i = 0; i < INPUT.length; i++) {
array.push(INPUT[i])
}
}
在这段代码中我们通过发送constroctor":{"name":"Array"}来绕过了第一个判断,随后程序在尝试创建/复制我们篡改过长度的的数组时由于消耗了太多的内存,最终导致应用给挂掉了。作为对策,原作者认为除了单纯的依赖try catch以外应当合理的对代码进行review写出不会出错的代码。
0x06 总结
- 如果提前知道可能会发生错误就应该早早地用try catch
- 对用户输入应当进行进行合理的escape
- 如果是JSON在访问属性之前应当进行数据类型验证
- 不要在毫无验证的情况下使用obj[INPUT]
- 即便是单纯的无限循环,放到Node.js就可能会是很严肃的问题