from:http://yurichev.com/RE-book.html
Chapter 5 printf() 与参数处理
现在让我们扩展"hello, world"(2)中的示例,将其中main()函数中printf的部分替换成这样
#include <stdio.h>
int main()
{
printf("a=%d; b=%d; c=%d", 1, 2, 3);
return 0;
};
5.1 x86: 3个参数
5.1.1 MSVC
在我们用MSVC 2010 Express编译后可以看到:
$SG3830 DB ’a=%d; b=%d; c=%d’, 00H
...
push 3
push 2
push 1
push OFFSET $SG3830
call _printf
add esp, 16 ; 00000010H
这和之前的代码几乎一样,但是我们现在可以看到printf() 的参数被反序压入了栈中。第一个参数被最后压入。
另外,在32bit的环境下int类型变量占4 bytes。
那么,这里有4个参数4*4=16 ——恰好在栈中占据了16bytes:一个32bit字符串指针,和3个int类型变量。
当函数执行完后,执行"ADD ESP, X"指令恢复栈指针寄存器(ESP 寄存器)。通常可以在这里推断函数参数的个数:用 X除以4。
当然,这只涉及__cdecl函数调用方式。
也可以在最后一个函数调用后,把几个"ADD ESP, X"指令合并成一个。
push a1
push a2
call ...
...
push a1
call ...
...
push a1
push a2
push a3
call ...
add esp, 24
5.1.2 MSVC 与 ollyDbg
现在我们来在OllyDbg中加载这个范例。我们可以尝试在MSVC 2012 加 /MD 参数编译这个示例,也就是链接MSVCR*.dll,那么我们就可以在debugger中清楚的看到调用的函数。
在OllyDbg中载入程序,最开始的断点在ntdll.dll中,接着按F9(run),然后第二个断点在CRT-code中。现在我们来找main()函数。
往下滚动屏幕,找到下图这段代码(MSVC把main()函数分配在代码段开始处) 见图5.3
点击 PUSH EBP指令,按下F2(设置断点)然后按下F9(run),通过这些操作来跳过CRT-code,因为我们现在还不必关注这部分。
按6次F8(step over)。见图5.4 现在EIP 指向了CALL printf的指令。和其他调试器一样,OllyDbg高亮了有值改变的寄存器。所以每次你按下F8,EIP都在改变然后它看起来便是红色的。ESP同时也在改变,因为它是指向栈的
栈中的数据又在哪?那么看一下调试器右下方的窗口:

图 5.1
然后我们可以看到有三列,栈的地址,元组数据,以及一些OllyDbg的注释,OllyDbg可以识别像printf()这样的字符串,以及后面的三个值。
右击选中字符串,然后点击”follow in dump”,然后字符串就会出现在左侧显示内存数据的地方,这些内存的数据可以被编辑。我们可以修改这些字符串,之后这个例子的结果就会变的不同,现在可能并不是很实用。但是作为练习却非常好,可以体会每部分是如何工作的。
再按一次F8(step over)
然后我们就可以看到输出

图5.2 执行printf()函数
让我们看看寄存器和栈是怎样变化的 见图5.5
EAX寄存器现在是0xD(13).这是正确的,printf()返回打印的字符,EIP也变了——
事实上现在指向CALL printf之后下一条指令的地址.ECX和EDX的值也改变了。显然,printf()函数的内部机制对它们进行了使用。
很重要的一点ESP的值并没有发生变化,栈的状态也是!我们可以清楚地看到字符串和相应的3个值还是在那里,实际上这就是cdecl调用方式。被调用的函数并不清楚栈中参数,因为这是调用体的任务。
再按一下F8执行ADD ESP, 10 见图5.6
ESP改变了,但是值还是在栈中!当然 没有必要用0或者别的数据填充这些值。
因为在栈指针寄存器之上的数据都是无用的。
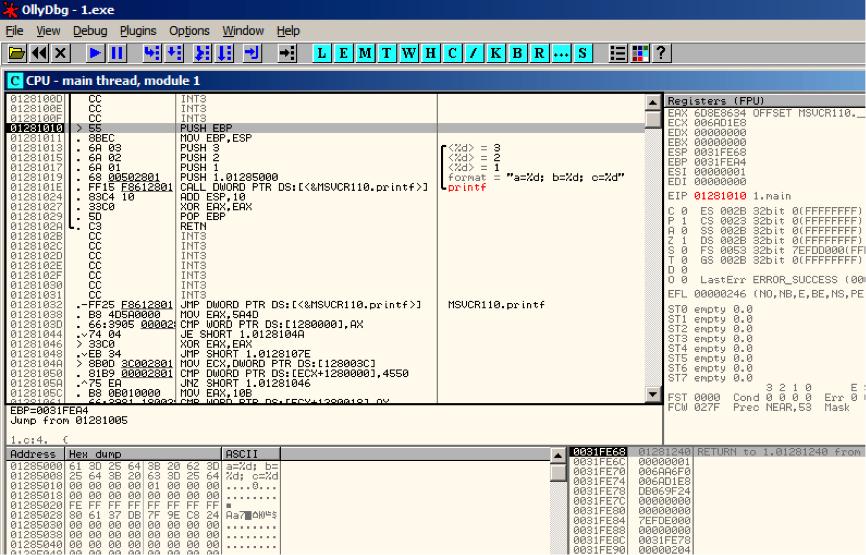
图5.3 OllyDbg:main()初始处
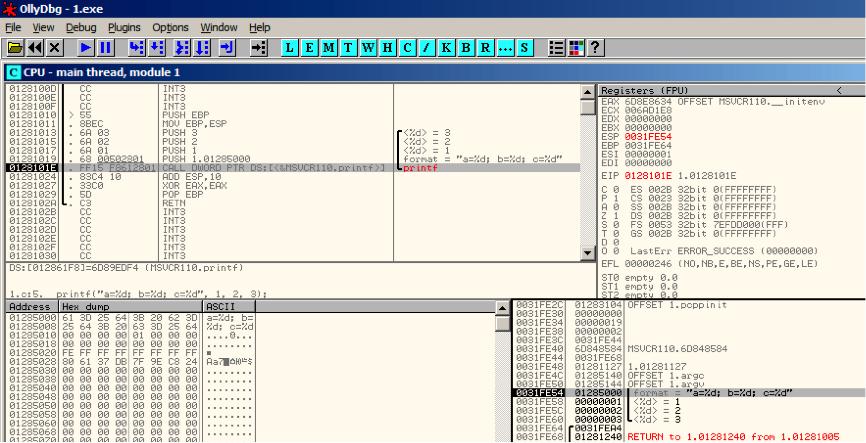
图5.4 OllyDbg:printf()执行时
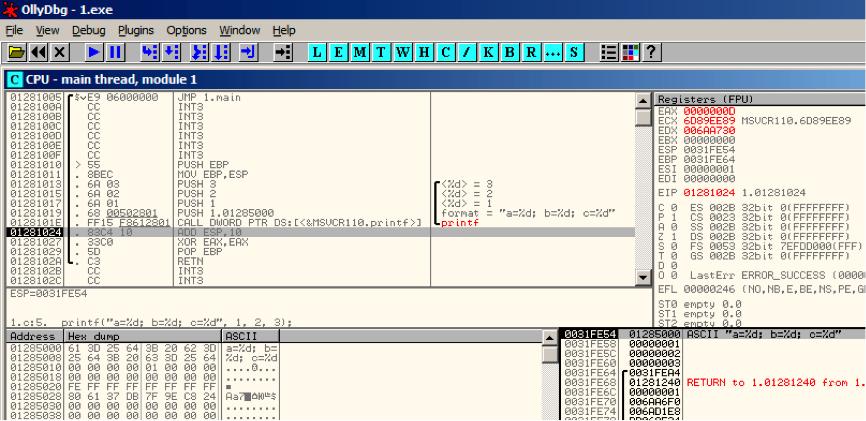
图5.5 Ollydbg:printf()执行后

图5.6 OllyDbg ADD ESP, 10执行完后
5.1.3 GCC
现在我们将同样的程序在linux下用GCC4.4.1编译后放入IDA看一下:
main proc near
var_10 = dword ptr -10h
var_C = dword ptr -0Ch
var_8 = dword ptr -8
var_4 = dword ptr -4
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 10h
mov eax, offset aADBDCD ; "a=%d; b=%d; c=%d"
mov [esp+10h+var_4], 3
mov [esp+10h+var_8], 2
mov [esp+10h+var_C], 1
mov [esp+10h+var_10], eax
call _printf
mov eax, 0
leave
retn
main endp
MSVC与GCC编译后代码的不同点只是参数入栈的方法不同,这里GCC不用PUSH/POP而是直接对栈操作。
5.1.4 GCC与GDB
接着我们尝试在linux中用GDB运行下这个示例程序。
-g 表示将debug信息插入可执行文件中
$ gcc 1.c -g -o 1
反编译:
$ gdb 1
GNU gdb (GDB) 7.6.1-ubuntu
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "i686-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /home/dennis/polygon/1...done.
表5.1 在printf()处设置断点
(gdb) b printf
Breakpoint 1 at 0x80482f0
Run 这里没有printf()函数的源码,所以GDB没法显示出源码,但是却可以这样做
(gdb) run
Starting program: /home/dennis/polygon/1
Breakpoint 1, __printf (format=0x80484f0 "a=%d; b=%d; c=%d") at printf.c:29
29 printf.c: No such file or directory.
打印10组栈中的元组数据,左边是栈中的地址
(gdb) x/10w $esp
0xbffff11c: 0x0804844a 0x080484f0 0x00000001 0x00000002
0xbffff12c: 0x00000003 0x08048460 0x00000000 0x00000000
0xbffff13c: 0xb7e29905 0x00000001
最开始的是返回地址(0x0804844a),我们可以确定在这里,于是可以反汇编这里的代码
(gdb) x/5i 0x0804844a
0x804844a <main+45>: mov $0x0,%eax
0x804844f <main+50>: leave
0x8048450 <main+51>: ret
0x8048451: xchg %ax,%ax
0x8048453: xchg %ax,%ax
两个XCHG指令,明显是一些垃圾数据,可以忽略 第二个(0x080484f0)是一处格式化字符串
(gdb) x/s 0x080484f0
0x80484f0: "a=%d; b=%d; c=%d"
而其他三个则是printf()函数的参数,另外的可能只是栈中的垃圾数据,但是也可能是其他函数的数据,例如它们的本地变量。这里可以忽略。 执行 finish ,表示执行到函数结束。在这里是执行到printf()完。
(gdb) finish
Run till exit from #0 __printf (format=0x80484f0 "a=%d; b=%d; c=%d") at printf.c:29
main () at 1.c:6
6 return 0;
Value returned is $2 = 13
GDB显示了printf()函数在eax中的返回值,这是打印字符的数量,就像在OllyDbg中一样。
我们同样看到了”return 0;” 及这在1.c文件中第6行所代表的含义。1.c文件就在当前目录下,GDB就在那找到了字符串。但是GDB又是怎么知道当前执行到了哪一行?
事实上这和编译器有关,当生成调试信息时,同样也保存了一张代码行号与指令地址的关系表。
查看EAX中储存的13:
(gdb) info registers
eax 0xd 13
ecx 0x0 0
edx 0x0 0
ebx 0xb7fc0000 -1208221696
esp 0xbffff120 0xbffff120
ebp 0xbffff138 0xbffff138
esi 0x0 0
edi 0x0 0
eip 0x804844a 0x804844a <main+45>
...
反汇编当前的指令
(gdb) disas
Dump of assembler code for function main:
0x0804841d <+0>: push %ebp
0x0804841e <+1>: mov %esp,%ebp
0x08048420 <+3>: and $0xfffffff0,%esp
0x08048423 <+6>: sub $0x10,%esp
0x08048426 <+9>: movl $0x3,0xc(%esp)
0x0804842e <+17>: movl $0x2,0x8(%esp)
0x08048436 <+25>: movl $0x1,0x4(%esp)
0x0804843e <+33>: movl $0x80484f0,(%esp)
0x08048445 <+40>: call 0x80482f0 <printf@plt>
=> 0x0804844a <+45>: mov $0x0,%eax
0x0804844f <+50>: leave
0x08048450 <+51>: ret
End of assembler dump.
GDB默认使用AT&T语法显示,当然也可以转换至intel:
(gdb) set disassembly-flavor intel
(gdb) disas
Dump of assembler code for function main:
0x0804841d <+0>: push ebp
0x0804841e <+1>: mov ebp,esp
0x08048420 <+3>: and esp,0xfffffff0
0x08048423 <+6>: sub esp,0x10
0x08048426 <+9>: mov DWORD PTR [esp+0xc],0x3
0x0804842e <+17>: mov DWORD PTR [esp+0x8],0x2
0x08048436 <+25>: mov DWORD PTR [esp+0x4],0x1
0x0804843e <+33>: mov DWORD PTR [esp],0x80484f0
0x08048445 <+40>: call 0x80482f0 <printf@plt>
=> 0x0804844a <+45>: mov eax,0x0
0x0804844f <+50>: leave
0x08048450 <+51>: ret
End of assembler dump.
执行下一条指令,GDB显示了结束大括号,代表着这里是函数结束部分。
(gdb) step
7 };
在执行完MOV EAX, 0后我们可以看到EAX就已经变为0了。
(gdb) info registers
eax 0x0 0
ecx 0x0 0
edx 0x0 0
ebx 0xb7fc0000 -1208221696
esp 0xbffff120 0xbffff120
ebp 0xbffff138 0xbffff138
esi 0x0 0
edi 0x0 0
eip 0x804844f 0x804844f <main+50>
...
5.2 x64: 8个参数
为了看其他参数如何通过栈传递的,我们再次修改代码将参数个数增加到9个(printf()格式化字符串和8个int 变量)
#include <stdio.h>
int main() {
printf("a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d
", 1, 2, 3, 4, 5, 6, 7, 8);
return 0;
};
5.2.1 MSVC
正如我们之前所见,在win64下开始的4个参数传递至RCX,RDX,R8,R9寄存器,
然而 MOV指令,替代PUSH指令。用来准备栈数据,所以值都是直接写入栈中
$SG2923 DB ’a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d’, 0aH, 00H
main PROC
sub rsp, 88
mov DWORD PTR [rsp+64], 8
mov DWORD PTR [rsp+56], 7
mov DWORD PTR [rsp+48], 6
mov DWORD PTR [rsp+40], 5
mov DWORD PTR [rsp+32], 4
mov r9d, 3
mov r8d, 2
mov edx, 1
lea rcx, OFFSET FLAT:$SG2923
call printf
; return 0
xor eax, eax
add rsp, 88
ret 0
main ENDP
_TEXT ENDS
END
表5.2:msvc 2010 x64
5.2.2 GCC
在*NIX系统,对于x86-64这也是同样的原理,除了前6个参数传递给了RDI,RSI,RDX,RCX,R8,R9寄存器。GCC将生成的代码字符指针写入了EDI而不是RDI(如果有的话)——我们在2.2.2节看到过这部分
同样我们也看到在寄存器EAX被清零前有个printf() call:
.LC0:
.string "a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d
"
main:
sub rsp, 40
mov r9d, 5
mov r8d, 4
mov ecx, 3
mov edx, 2
mov esi, 1
mov edi, OFFSET FLAT:.LC0
xor eax, eax ; number of vector registers passed
mov DWORD PTR [rsp+16], 8
mov DWORD PTR [rsp+8], 7
mov DWORD PTR [rsp], 6
call printf
; return 0
xor eax, eax
add rsp, 40
ret
表5.3:GCC 4.4.6 –o 3 x64
5.2.3 GCC + GDB
让我们在GDB中尝试这个例子。
$ gcc -g 2.c -o 2
反编译:
$ gdb 2
GNU gdb (GDB) 7.6.1-ubuntu
Copyright (C) 2013 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>...
Reading symbols from /home/dennis/polygon/2...done.
表5.4:在printf()处下断点,然后run
(gdb) b printf
Breakpoint 1 at 0x400410
(gdb) run
Starting program: /home/dennis/polygon/2
Breakpoint 1, __printf (format=0x400628 "a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d
") at
printf.c:29
29 printf.c: No such file or directory.
寄存器RSI/RDX/RCX/R8/R9都有应有的值,RIP则是printf()函数地址
(gdb) info registers
rax 0x0 0
rbx 0x0 0
rcx 0x3 3
rdx 0x2 2
rsi 0x1 1
rdi 0x400628 4195880
rbp 0x7fffffffdf60 0x7fffffffdf60
rsp 0x7fffffffdf38 0x7fffffffdf38
r8 0x4 4
r9 0x5 5
r10 0x7fffffffdce0 140737488346336
r11 0x7ffff7a65f60 140737348263776
r12 0x400440 4195392
r13 0x7fffffffe040 140737488347200
r14 0x0 0
r15 0x0 0
rip 0x7ffff7a65f60 0x7ffff7a65f60 <__printf>
...
表5.5 检查格式化字符串
(gdb) x/s $rdi
0x400628: "a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d
"
用 x/g命令显示栈内容
(gdb) x/10g $rsp
0x7fffffffdf38: 0x0000000000400576 0x0000000000000006
0x7fffffffdf48: 0x0000000000000007 0x00007fff00000008
0x7fffffffdf58: 0x0000000000000000 0x0000000000000000
0x7fffffffdf68: 0x00007ffff7a33de5 0x0000000000000000
0x7fffffffdf78: 0x00007fffffffe048 0x0000000100000000
与之前一样,第一个栈元素是返回地址,我们也同时也看到在高32位的8也没有被清除。 0x00007fff00000008,这是因为是32位int类型的,因此,高寄存器或堆栈部分可能包含一些随机垃圾数值。
printf()函数执行之后将返回控制,GDB会显示整个main()函数。
(gdb) set disassembly-flavor intel
(gdb) disas 0x0000000000400576
Dump of assembler code for function main:
0x000000000040052d <+0>: push rbp
0x000000000040052e <+1>: mov rbp,rsp
0x0000000000400531 <+4>: sub rsp,0x20
0x0000000000400535 <+8>: mov DWORD PTR [rsp+0x10],0x8
0x000000000040053d <+16>: mov DWORD PTR [rsp+0x8],0x7
0x0000000000400545 <+24>: mov DWORD PTR [rsp],0x6
0x000000000040054c <+31>: mov r9d,0x5
0x0000000000400552 <+37>: mov r8d,0x4
0x0000000000400558 <+43>: mov ecx,0x3
0x000000000040055d <+48>: mov edx,0x2
0x0000000000400562 <+53>: mov esi,0x1
0x0000000000400567 <+58>: mov edi,0x400628
0x000000000040056c <+63>: mov eax,0x0
0x0000000000400571 <+68>: call 0x400410 <printf@plt>
0x0000000000400576 <+73>: mov eax,0x0
0x000000000040057b <+78>: leave
0x000000000040057c <+79>: ret
End of assembler dump.
执行完printf()后,就会清零EAX,然后发现EAX早已为0,RIP现在则指向LEAVE指令。
(gdb) finish
Run till exit from #0 __printf (format=0x400628 "a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d
n") at printf.c:29
a=1; b=2; c=3; d=4; e=5; f=6; g=7; h=8
main () at 2.c:6
6 return 0;
Value returned is $1 = 39
(gdb) next
7 };
(gdb) info registers
rax 0x0 0
rbx 0x0 0
rcx 0x26 38
rdx 0x7ffff7dd59f0 140737351866864
rsi 0x7fffffd9 2147483609
rdi 0x0 0
rbp 0x7fffffffdf60 0x7fffffffdf60
rsp 0x7fffffffdf40 0x7fffffffdf40
r8 0x7ffff7dd26a0 140737351853728
r9 0x7ffff7a60134 140737348239668
r10 0x7fffffffd5b0 140737488344496
r11 0x7ffff7a95900 140737348458752
r12 0x400440 4195392
r13 0x7fffffffe040 140737488347200
r14 0x0 0
r15 0x0 0
rip 0x40057b 0x40057b <main+78>
...
5.3 ARM:3个参数
习惯上,ARM传递参数的规则(参数调用)如下:前4个参数传递给了R0-R3寄存器,其余的参数则在栈中。这和fastcall或者win64传递参数很相似
5.3.1 Non-optimizing Keil + ARM mode(非优化keil编译模式 + ARM环境)
.text:00000014 printf_main1
.text:00000014 10 40 2D E9 STMFD SP!, {R4,LR}
.text:00000018 03 30 A0 E3 MOV R3, #3
.text:0000001C 02 20 A0 E3 MOV R2, #2
.text:00000020 01 10 A0 E3 MOV R1, #1
.text:00000024 1D 0E 8F E2 ADR R0, aADBDCD ; "a=%d; b=%d; c=%d
"
.text:00000028 0D 19 00 EB BL __2printf
.text:0000002C 10 80 BD E8 LDMFD SP!, {R4,PC}
所以 前四个参数按照它们的顺序传递给了R0-R3, printf()中的格式化字符串指针在R0中,然后1在R1,2在R2,3在R3. 到目前为止没有什么不寻常的。
5.3.2 Optimizing Keil + ARM mode(优化的keil编译模式 + ARM环境)
.text:00000014 EXPORT printf_main1
.text:00000014 printf_main1
.text:00000014 03 30 A0 E3 MOV R3, #3
.text:00000018 02 20 A0 E3 MOV R2, #2
.text:0000001C 01 10 A0 E3 MOV R1, #1
.text:00000020 1E 0E 8F E2 ADR R0, aADBDCD ; "a=%d; b=%d; c=%d
"
.text:00000024 CB 18 00 EA B __2printf
表5.7: Optimizing Keil + ARM mode
这是在针对ARM optimized (-O3)版本下的,我们可以B作为最后一个指令而不是熟悉的BL。另外一个不同之处在optimized与之前的(compiled without optimization)对比发现函数prologue 和 epilogue(储存R0和LR值的寄存器),B指令仅仅跳向另一处地址,没有任何关于LR寄存器的操作,也就是说它和x86中的jmp相似,为什么会这样?因为代码就是这样,事实上,这和前面相似,主要有两点原因 1)不管是栈还是SP(栈指针),都有被修改。2)printf()的调用是最后的指令,所以之后便没有了。完成之后,printf()函数就返回到LR储存的地址处。但是指针地址从函数调用的地方转移到了LR中!接着就会从printf()到那里。结果,我们不需要保存LR,因为我们没有必要修改LR。因为除了printf()函数外没有其他函数了。另外,除了这个调用外,我们不需要再做别的。这就是为什么这样编译是可行的。
5.3.3 Optimizing Keil + thumb mode
.text:0000000C printf_main1
.text:0000000C 10 B5 PUSH {R4,LR}
.text:0000000E 03 23 MOVS R3, #3
.text:00000010 02 22 MOVS R2, #2
.text:00000012 01 21 MOVS R1, #1
.text:00000014 A4 A0 ADR R0, aADBDCD ; "a=%d; b=%d; c=%d
"
.text:00000016 06 F0 EB F8 BL __2printf
.text:0000001A 10 BD POP {R4,PC}
表5.8:Optimizing Keil + thumb mode
和non-optimized for ARM mode代码没什么明显的区别
5.4 ARM: 8 arguments
我们再用之前9个参数的那个例子
void printf_main2()
{
printf("a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%d; h=%d
", 1, 2, 3, 4, 5, 6, 7, 8);
};
5.4.1 Optimizing Keil: ARM mode
.text:00000028 printf_main2
.text:00000028
.text:00000028 var_18 = -0x18
.text:00000028 var_14 = -0x14
.text:00000028 var_4 = -4
.text:00000028
.text:00000028 04 E0 2D E5 STR LR, [SP,#var_4]!
.text:0000002C 14 D0 4D E2 SUB SP, SP, #0x14
.text:00000030 08 30 A0 E3 MOV R3, #8
.text:00000034 07 20 A0 E3 MOV R2, #7
.text:00000038 06 10 A0 E3 MOV R1, #6
.text:0000003C 05 00 A0 E3 MOV R0, #5
.text:00000040 04 C0 8D E2 ADD R12, SP, #0x18+var_14
.text:00000044 0F 00 8C E8 STMIA R12, {R0-R3}
.text:00000048 04 00 A0 E3 MOV R0, #4
.text:0000004C 00 00 8D E5 STR R0, [SP,#0x18+var_18]
.text:00000050 03 30 A0 E3 MOV R3, #3
.text:00000054 02 20 A0 E3 MOV R2, #2
.text:00000058 01 10 A0 E3 MOV R1, #1
.text:0000005C 6E 0F 8F E2 ADR R0, aADBDCDDDEDFDGD ; "a=%d; b=%d; c=%d; d=%d;
e=%d; f=%d; g=%"...
.text:00000060 BC 18 00 EB BL __2printf
.text:00000064 14 D0 8D E2 ADD SP, SP, #0x14
.text:00000068 04 F0 9D E4 LDR PC, [SP+4+var_4],#4
这些代码可以分成几个部分:
Function prologue:
最开始的”STR LR, [SP,#var_4]!”指令将LR储存在栈中,因为我们将用这个寄存器调用printf()。
第二个” SUB SP, SP, #0x14”指令减了SP(栈指针),为了在栈上分配0x14(20)bytes的内存,实际上我们需要传递5个 32-bit的数据通过栈传递给printf()函数,而且每个占4bytes,也就是5*4=20。另外4个32-bit的数据将会传递给寄存器。
通过栈传递5,6,7和8:
然后,5,6,7,8分别被写入了R0,R1,R2及R3寄存器。然后”ADD R12, SP,#0x18+var_14”指令将栈中指针的地址写入,并且在这里会向R12写入4个值,var_14是一个汇编宏,相当于0x14,这些都由IDA简明的创建表示访问栈的变量,var_?在IDA中表示栈中的本地变量,所以SP+4将被写入R12寄存器。下一步的”STMIA R12, R0-R3”指令将R0-R3寄存器的内容写在了R2指向的指针处。STMIA指令指Store Multiple Increment After, Increment After指R12寄存器在有值写入后自增4。
通过栈传递4:
4存在R0中,然后这个值在”STR R0, [SP,#0x18+var_18]”指令帮助下,存在了栈上,var_18是0x18,偏移量为0.所以R0寄存器中的值将会写在SP指针指向的指针处。
通过寄存器传递1,2,3:
开始3个数(a,b,c)(分别是1,2,3)正好在printf()函数调用前被传递到了R1,R2,R3寄存器中。 然后另外5个值通过栈传递。
printf() 调用
Function epilogue:
“ADD SP, SP, #0x14”指令将SP指针返回到之前的指针处,因此清除了栈,当然,栈中之前写入的数据还在那,但是当后来的函数被调用时那里则会被重写。 “LDR PC, [SP+4+var_4],#4"指令将LR中储存的值载入到PC指针,因此函数结束。
5.4.2 Optimizing Keil: thumb mode
.text:0000001C printf_main2
.text:0000001C
.text:0000001C var_18 = -0x18
.text:0000001C var_14 = -0x14
.text:0000001C var_8 = -8
.text:0000001C
.text:0000001C 00 B5 PUSH {LR}
.text:0000001E 08 23 MOVS R3, #8
.text:00000020 85 B0 SUB SP, SP, #0x14
.text:00000022 04 93 STR R3, [SP,#0x18+var_8]
.text:00000024 07 22 MOVS R2, #7
.text:00000026 06 21 MOVS R1, #6
.text:00000028 05 20 MOVS R0, #5
.text:0000002A 01 AB ADD R3, SP, #0x18+var_14
.text:0000002C 07 C3 STMIA R3!, {R0-R2}
.text:0000002E 04 20 MOVS R0, #4
.text:00000030 00 90 STR R0, [SP,#0x18+var_18]
.text:00000032 03 23 MOVS R3, #3
.text:00000034 02 22 MOVS R2, #2
.text:00000036 01 21 MOVS R1, #1
.text:00000038 A0 A0 ADR R0, aADBDCDDDEDFDGD ; "a=%d; b=%d; c=%d; d=%d; e=%d; f=%d; g=%"...
.text:0000003A 06 F0 D9 F8 BL __2printf
.text:0000003E
.text:0000003E loc_3E ; CODE XREF: example13_f+16
.text:0000003E 05 B0 ADD SP, SP, #0x14
.text:00000040 00 BD POP {PC}
几乎和之前的例子是一样的,然后这是thumb 代码,值入栈的确不同:先是8,然后5,6,7,第三个是4。
5.4.3 Optimizing Xcode (LLVM): ARM mode
__text:0000290C _printf_main2
__text:0000290C
__text:0000290C var_1C = -0x1C
__text:0000290C var_C = -0xC
__text:0000290C
__text:0000290C 80 40 2D E9 STMFD SP!, {R7,LR}
__text:00002910 0D 70 A0 E1 MOV R7, SP
__text:00002914 14 D0 4D E2 SUB SP, SP, #0x14
__text:00002918 70 05 01 E3 MOV R0, #0x1570
__text:0000291C 07 C0 A0 E3 MOV R12, #7
__text:00002920 00 00 40 E3 MOVT R0, #0
__text:00002924 04 20 A0 E3 MOV R2, #4
__text:00002928 00 00 8F E0 ADD R0, PC, R0
__text:0000292C 06 30 A0 E3 MOV R3, #6
__text:00002930 05 10 A0 E3 MOV R1, #5
__text:00002934 00 20 8D E5 STR R2, [SP,#0x1C+var_1C]
__text:00002938 0A 10 8D E9 STMFA SP, {R1,R3,R12}
__text:0000293C 08 90 A0 E3 MOV R9, #8
__text:00002940 01 10 A0 E3 MOV R1, #1
__text:00002944 02 20 A0 E3 MOV R2, #2
__text:00002948 03 30 A0 E3 MOV R3, #3
__text:0000294C 10 90 8D E5 STR R9, [SP,#0x1C+var_C]
__text:00002950 A4 05 00 EB BL _printf
__text:00002954 07 D0 A0 E1 MOV SP, R7
__text:00002958 80 80 BD E8 LDMFD SP!, {R7,PC}
几乎和我们之前遇到的一样,除了STMFA(Store Multiple Full Ascending)指令,它和STMIB(Store Multiple Increment Before)指令一样,这个指令直到下个寄存器的值写入内存时会增加SP寄存器中的值,但是反过来却不同。
另外一个地方我们可以轻松的发现指令是随机分布的,例如,R0寄存器中的值在三个地方初始,在0x2918,0x2920,0x2928。而这一个指令就可以搞定。然而,optimizing compiler有它自己的原因,对于如何更好的放置指令,通常,处理器尝试同时执行并行的指令,例如像” MOVT R0, #0”和” ADD R0, PC,R0”就不能同时执行了,因为它们同时都在修改R0寄存器,另一方面”MOVT R0, #0”和”MOV R2, #4”指令却可以同时执行,因为执行效果并没有任何冲突。 大概,编译器就是这样尝试编译的,可能。
5.4.4 Optimizing Xcode (LLVM): thumb-2 mode
__text:00002BA0 _printf_main2
__text:00002BA0
__text:00002BA0 var_1C = -0x1C
__text:00002BA0 var_18 = -0x18
__text:00002BA0 var_C = -0xC
__text:00002BA0
__text:00002BA0 80 B5 PUSH {R7,LR}
__text:00002BA2 6F 46 MOV R7, SP
__text:00002BA4 85 B0 SUB SP, SP, #0x14
__text:00002BA6 41 F2 D8 20 MOVW R0, #0x12D8
__text:00002BAA 4F F0 07 0C MOV.W R12, #7
__text:00002BAE C0 F2 00 00 MOVT.W R0, #0
__text:00002BB2 04 22 MOVS R2, #4
__text:00002BB4 78 44 ADD R0, PC ; char *
__text:00002BB6 06 23 MOVS R3, #6
__text:00002BB8 05 21 MOVS R1, #5
__text:00002BBA 0D F1 04 0E ADD.W LR, SP, #0x1C+var_18
__text:00002BBE 00 92 STR R2, [SP,#0x1C+var_1C]
__text:00002BC0 4F F0 08 09 MOV.W R9, #8
__text:00002BC4 8E E8 0A 10 STMIA.W LR, {R1,R3,R12}
__text:00002BC8 01 21 MOVS R1, #1
__text:00002BCA 02 22 MOVS R2, #2
__text:00002BCC 03 23 MOVS R3, #3
__text:00002BCE CD F8 10 90 STR.W R9, [SP,#0x1C+var_C]
__text:00002BD2 01 F0 0A EA BLX _printf
__text:00002BD6 05 B0 ADD SP, SP, #0x14
__text:00002BD8 80 BD POP {R7,PC}
几乎和前面的例子相同,除了thumb-instructions在这里被替代使用了
5.5 by the way
值得一提的是,这些x86,x64,fastcall和ARM传递参数的不同表现了CPU并不在意函数参数是怎样传递的,同样也假想编译器可能用特殊的结构传送参数而一点也不是通过栈。
Chapter 6 scanf()
现在我们来使用scanf()。
#include <stdio.h>
int main()
{
int x;
printf ("Enter X:
");
scanf ("%d", &x);
printf ("You entered %d...
", x);
return 0;
};
好吧,我承认现在使用scanf()是不明智的,但是我想说明如何把指针传递给int变量。
6.1 关于指针
这是计算机科学中最基础的概念之一。通常,大数组、结构或对象经常被传递给其它函数,而传递它们的地址要更加简单。更重要的是:如果调用函数要修改数组或结构中的数据,并且作为整体返回,那么最简单的办法就是把数组或结构的地址传递给函数,让函数进行修改。
在C/C++中指针就是某处内存的地址。
在x86中,地址是以32位数表示的(占4字节);在x86-64中是64位数(占8字节)。顺便一说,这也是为什么有些人在改用x86-64时感到愤怒——x64架构中所有的指针需要的空间是原来的两倍。
通过某种方法,只使用无类型指针也是可行的。例如标准C函数memcpy(),用于把一个区块复制到另外一个区块上,需要两个void*型指针作为输入,因为你无法预知,也无需知道要复制区块的类型,区块的大小才是重要的。
当函数需要一个以上的返回值时也经常用到指针(等到第九章再讲)。scanf()就是这样,函数除了要显示成功读入的字符个数外,还要返回全部值。
在C/C++中,指针类型只是用于在编译阶段进行类型检查。本质上,在已编译的代码中并不包含指针类型的信息。
6.2 x86
6.2.1 MSVC
MVSC 2010编译后得到下面代码
CONST SEGMENT
$SG3831 DB ’Enter X:’, 0aH, 00H
$SG3832 DB ’%d’, 00H
35
6.2. X86 CHAPTER 6. SCANF()
$SG3833 DB ’You entered %d...’, 0aH, 00H
CONST ENDS
PUBLIC _main
EXTRN _scanf:PROC
EXTRN _printf:PROC
; Function compile flags: /Odtp
_TEXT SEGMENT
_x$ = -4 ; size = 4
_main PROC
push ebp
mov ebp, esp
push ecx
push OFFSET $SG3831 ; ’Enter X:’
call _printf
add esp, 4
lea eax, DWORD PTR _x$[ebp]
push eax
push OFFSET $SG3832 ; ’%d’
call _scanf
add esp, 8
mov ecx, DWORD PTR _x$[ebp]
push ecx
push OFFSET $SG3833 ; ’You entered %d...’
call _printf
add esp, 8
; return 0
xor eax, eax
mov esp, ebp
pop ebp
ret 0
_main ENDP
_TEXT ENDS
X是局部变量。
C/C++标准告诉我们它只对函数内部可见,无法从外部访问。习惯上,局部变量放在栈中。也可能有其他方法,但在x86中是这样。
函数序言后下一条指令PUSH ECX目的并不是要存储ECX的状态(注意程序结尾没有与之相对的POP ECX)。
事实上这条指令仅仅是在栈中分配了4字节用于存储变量x。
变量x可以用宏_x$来访问(等于-4),EBP寄存器指向当前栈帧。
在一个函数执行完之后,EBP将指向当前栈帧,就无法通过EBP+offset来访问局部变量和函数参数了。
也可以使用ESP寄存器,但由于它经常变化所以使用不方便。所以说在函数刚开始时,EBP的值保存了此时ESP的值。
下面是一个非常典型的32位栈帧结构 ... ... EBP-8 local variable #2, marked in IDA as var_8 EBP-4 local variable #1, marked in IDA as var_4 EBP saved value of EBP EBP+4 return address EBP+8 argument#1, marked in IDA as arg_0 EBP+0xC argument#2, marked in IDA as arg_4 EBP+0x10 argument#3, marked in IDA as arg_8 ... ...
在我们的例子中,scanf()有两个参数。
第一个参数是指向"%d"的字符串指针,第二个是变量x的地址。
首先,lea eax, DWORD PTR _x$[ebp]指令将变量x的地址放入EAX寄存器。LEA作用是"取有效地址",然而之后的主要用途有所变化(b.6.2)。
可以说,LEA在这里只是把EBP的值与宏_x$的值相乘,并存储在EAX寄存器中。
lea eax, [ebp-4]也是一样。
EBP的值减去4,结果放在EAX寄存器中。接着EAX寄存器的值被压入栈中,再调用printf()。
之后,printf()被调用。第一个参数是一个字符串指针:"You entered %d …"。
第二个参数是通过mov ecx, [ebp-4]使用的,这个指令把变量x的内容传给ECX而不是它的地址。
然后,ECX的值放入栈中,接着最后一次调用printf()。
6.2.2 MSVC+OllyDbg
让我们在OllyDbg中使用这个例子。首先载入程序,按F8直到进入我们的可执行文件而不是ntdll.dll。往下滚动屏幕找到main()。点击第一条指令(PUSH EBP),按F2,再按F9,触发main()开始处的断点。
让我们来跟随到准备变量x的地址的位置。图6.2
可以右击寄存器窗口的EAX,再点击"堆栈窗口中跟随"。这个地址会在堆栈窗口中显示。观察,这是局部栈中的一个变量。我在图中用红色箭头标出。这里是一些无用数据(0x77D478)。PUSH指令将会把这个栈元素的地址压入栈中。然后按F8直到scanf()函数执行完。在scanf()执行时,我们要在命令行窗口中输入,例如输入123。
图6.1 命令行输出
scanf()在这里执行。图6.3。scanf()在EAX中返回1,这意味着成功读入了一个值。现在我们关心的那个栈元素中的值是0x7B(123)。
接下来,这个值从栈中复制到ECX寄存器中,然后传递给printf()。图6.4
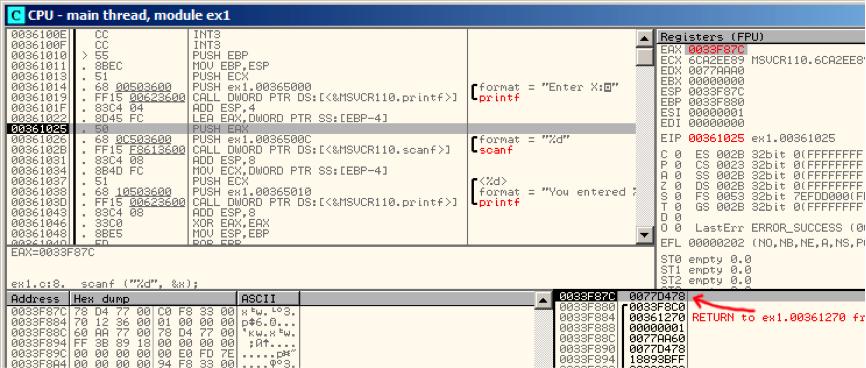
图6.2 OllyDbg:计算局部变量的地址
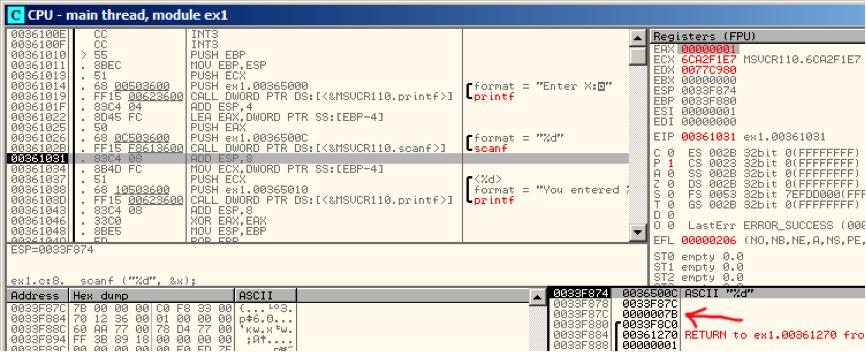
图6.3:OllyDbg:scanf()执行

图6.4:OllyDbg:准备把值传递给printf()
6.2.3 GCC
让我们在Linux GCC 4.4.1下编译这段代码
GCC把第一个调用的printf()替换成了puts(),原因在2.3.3节中讲过了。
和之前一样,参数都是用MOV指令放入栈中。
6.3 x64
和原来一样,只是传递参数时不使用栈而使用寄存器。
6.3.1 MSVC
_DATA SEGMENT
$SG1289 DB ’Enter X:’, 0aH, 00H
$SG1291 DB ’%d’, 00H
$SG1292 DB ’You entered %d...’, 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
x$ = 32
main PROC
$LN3:
sub rsp, 56
lea rcx, OFFSET FLAT:$SG1289 ; ’Enter X:’
call printf
lea rdx, QWORD PTR x$[rsp]
lea rcx, OFFSET FLAT:$SG1291 ; ’%d’
call scanf
mov edx, DWORD PTR x$[rsp]
lea rcx, OFFSET FLAT:$SG1292 ; ’You entered %d...’
call printf
; return 0
xor eax, eax
add rsp, 56
ret 0
main ENDP
_TEXT ENDS
6.3.2 GCC
.LC0:
.string "Enter X:"
.LC1:
.string "%d"
.LC2:
.string "You entered %d...
"
main:
sub rsp, 24
mov edi, OFFSET FLAT:.LC0 ; "Enter X:"
call puts
lea rsi, [rsp+12]
mov edi, OFFSET FLAT:.LC1 ; "%d"
xor eax, eax
call __isoc99_scanf
mov esi, DWORD PTR [rsp+12]
mov edi, OFFSET FLAT:.LC2 ; "You entered %d...
"
xor eax, eax
call printf
; return 0
xor eax, eax
add rsp, 24
ret
6.4 ARM
6.4.1 keil优化+thumb mode
.text:00000042 scanf_main
.text:00000042
.text:00000042 var_8 = -8
.text:00000042
.text:00000042 08 B5 PUSH {R3,LR}
.text:00000044 A9 A0 ADR R0, aEnterX ; "Enter X:
"
.text:00000046 06 F0 D3 F8 BL __2printf
.text:0000004A 69 46 MOV R1, SP
.text:0000004C AA A0 ADR R0, aD ; "%d"
.text:0000004E 06 F0 CD F8 BL __0scanf
.text:00000052 00 99 LDR R1, [SP,#8+var_8]
.text:00000054 A9 A0 ADR R0, aYouEnteredD___ ; "You entered %d...
"
.text:00000056 06 F0 CB F8 BL __2printf
.text:0000005A 00 20 MOVS R0, #0
.text:0000005C 08 BD POP {R3,PC}
必须把一个指向int变量的指针传递给scanf(),这样才能通过这个指针返回一个值。Int是一个32位的值,所以我们在内存中需要4字节存储,并且正好符合32位的寄存器。局部变量x的空间分配在栈中,IDA把他命名为var_8。然而并不需要分配空间,因为栈指针指向的空间可以被立即使用。所以栈指针的值被复制到R1寄存器中,然后和格式化字符串一起送入scanf()。然后LDR指令将这个值从栈中送入R1寄存器,用以送入printf()中。
用ARM-mode和Xcode LLVM编译的代码区别不大,这里略去。
6.5 Global Variables
如果之前的例子中的x变量不再是本地变量而是全局变量呢?那么就有机会接触任何指针,不仅仅是函数体,全局变量被认为anti-pattern(通常被认为是一个不好的习惯),但是为了试验,我们可以这样做。
#include <stdio.h>
int x;
int main()
{
printf ("Enter X:
");
scanf ("%d", &x);
printf ("You entered %d...
", x);
return 0;
};
6.5.1 MSVC: x86
_DATA SEGMENT
COMM _x:DWORD
$SG2456 DB ’Enter X:’, 0aH, 00H
$SG2457 DB ’%d’, 00H
$SG2458 DB ’You entered %d...’, 0aH, 00H
_DATA ENDS
PUBLIC _main
EXTRN _scanf:PROC
EXTRN _printf:PROC
; Function compile flags: /Odtp
_TEXT SEGMENT
_main PROC
push ebp
mov ebp, esp
push OFFSET $SG2456
call _printf
add esp, 4
push OFFSET _x
push OFFSET $SG2457
call _scanf
add esp, 8
mov eax, DWORD PTR _x
push eax
push OFFSET $SG2458
call _printf
add esp, 8
xor eax, eax
pop ebp
ret 0
_main ENDP
_TEXT ENDS
现在x变量被定义为在_DATA部分,局部堆栈不允许再分配任何内存,除了直接访问内存所有通过栈的访问都不被允许。在执行的文件中全局变量还未初始化(实际上,我们为什么要在执行文件中为未初始化的变量分配一块?)但是当访问这里时,系统会在这里分配一块0值。
现在让我们明白的来分配变量吧"
int x=10; // default value
我们得到:
_DATA SEGMENT
_x DD 0aH
...
这里我们看见一个双字节的值0xA(DD 表示双字节 = 32bit)
如果你在IDA中打开compiled.exe,你会发现x变量被放置在_DATA块的开始处,接着你就会看见文本字符串。
如果你在IDA中打开之前例子中的compiled.exe中X变量没有定义的地方,你就会看见像这样的东西:
.data:0040FA80 _x dd ? ; DATA XREF: _main+10
.data:0040FA80 ; _main+22
.data:0040FA84 dword_40FA84 dd ? ; DATA XREF: _memset+1E
.data:0040FA84 ; unknown_libname_1+28
.data:0040FA88 dword_40FA88 dd ? ; DATA XREF: ___sbh_find_block+5
.data:0040FA88 ; ___sbh_free_block+2BC
.data:0040FA8C ; LPVOID lpMem
.data:0040FA8C lpMem dd ? ; DATA XREF: ___sbh_find_block+B
.data:0040FA8C ; ___sbh_free_block+2CA
.data:0040FA90 dword_40FA90 dd ? ; DATA XREF: _V6_HeapAlloc+13
.data:0040FA90 ; __calloc_impl+72
.data:0040FA94 dword_40FA94 dd ? ; DATA XREF: ___sbh_free_block+2FE
被_x替换了?其它变量也并未要求初始化,这也就是说在载入exe至内存后,在这里有一块针对所有变量的空间,并且还有一些随机的垃圾数据。但在在exe中这些没有初始化的变量并不影响什么,比如它适合大数组。
6.5.2 MSVC: x86 + OllyDbg
到这里事情就变得简单了(见表6.5),变量都在data部分,顺便说一句,在PUSH指令后,压入x的地址,被执行后,地址将会在栈中显示,那么右击元组数据,点击"Fllow in dump",然后变量就会在左侧内存窗口显示.
在命令行窗口中输入123后,这里就会显示0x7B
但是为什么第一个字节是7B?合理的猜测,这里会有一组00 00 7B,被称为是字节顺序,然后在x86中使用的是小端,也就是说低位数据先写,高位数据后写。
不一会,这里的32-bit值就会载入到EAX中,然后被传递给printf().
X变量地址是0xDC3390.在OllyDbg中我们看进程内存映射(Alt-M),然后发现这个地在PE文件.data结构处。见表6.6
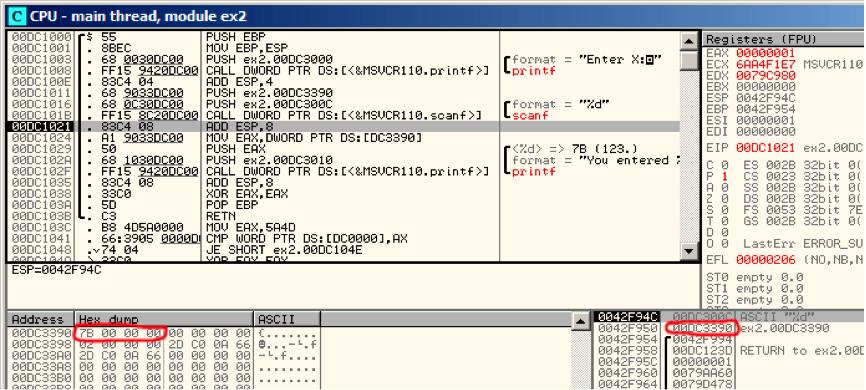
表6.5 OllyDbg: scanf()执行后
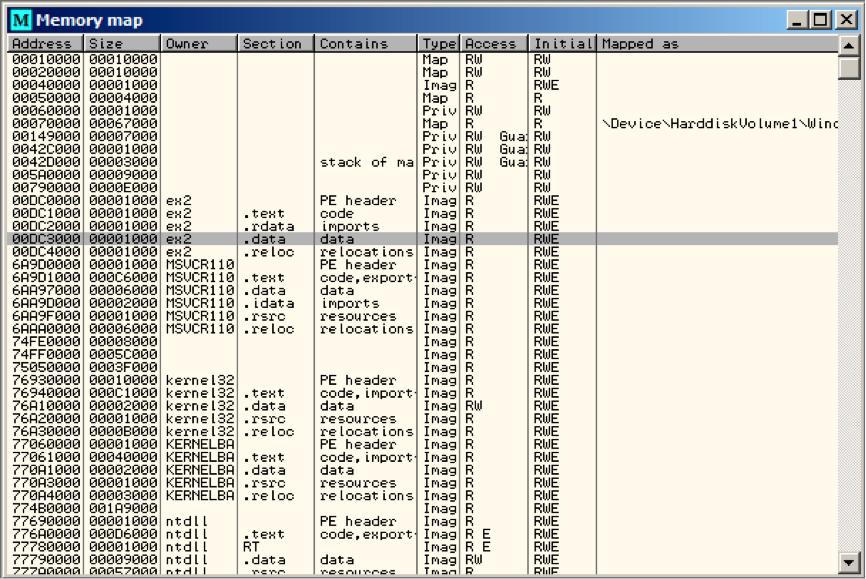
表6.6: OllyDbg 进程内存映射
6.5.3 GCC: x86
这和linux中几乎是一样的,除了segment的名称和属性:未初始化变量被放置在_bss部分。
在ELF文件格式中,这部分数据有这样的属性:
; Segment type: Uninitialized
; Segment permissions: Read/Write
如果静态的分配一个值,比如10,它将会被放在_data部分,这部分有下面的属性:
; Segment type: Pure data
; Segment permissions: Read/Write
6.5.4 MSVC: x64
_DATA SEGMENT
COMM x:DWORD
$SG2924 DB ’Enter X:’, 0aH, 00H
$SG2925 DB ’%d’, 00H
$SG2926 DB ’You entered %d...’, 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
main PROC
$LN3:
sub rsp, 40
lea rcx, OFFSET FLAT:$SG2924 ; ’Enter X:’
call printf
lea rdx, OFFSET FLAT:x
lea rcx, OFFSET FLAT:$SG2925 ; ’%d’
call scanf
mov edx, DWORD PTR x
lea rcx, OFFSET FLAT:$SG2926 ; ’You entered %d...’
call printf
; return 0
xor eax, eax
add rsp, 40
ret 0
main ENDP
_TEXT ENDS
几乎和x86中的代码是一样的,发现x变量的地址传递给scanf()用的是LEA指令,尽管第二处传递给printf()变量时用的是MOV指令,"DWORD PTR"——是汇编语言中的一部分(和机器码没有联系)。这就表示变量数据类型是32-bit,于是MOV指令就被编码了。
6.5.5 ARM:Optimizing Keil + thumb mode
.text:00000000 ; Segment type: Pure code
.text:00000000 AREA .text, CODE
...
.text:00000000 main
.text:00000000 PUSH {R4,LR}
.text:00000002 ADR R0, aEnterX ; "Enter X:
"
.text:00000004 BL __2printf
.text:00000008 LDR R1, =x
.text:0000000A ADR R0, aD ; "%d"
.text:0000000C BL __0scanf
.text:00000010 LDR R0, =x
.text:00000012 LDR R1, [R0]
.text:00000014 ADR R0, aYouEnteredD___ ; "You entered %d...
"
.text:00000016 BL __2printf
.text:0000001A MOVS R0, #0
.text:0000001C POP {R4,PC}
...
.text:00000020 aEnterX DCB "Enter X:",0xA,0 ; DATA XREF: main+2
.text:0000002A DCB 0
.text:0000002B DCB 0
.text:0000002C off_2C DCD x ; DATA XREF: main+8
.text:0000002C ; main+10
.text:00000030 aD DCB "%d",0 ; DATA XREF: main+A
.text:00000033 DCB 0
.text:00000034 aYouEnteredD___ DCB "You entered %d...",0xA,0 ; DATA XREF: main+14
.text:00000047 DCB 0
.text:00000047 ; .text ends
.text:00000047
...
.data:00000048 ; Segment type: Pure data
.data:00000048 AREA .data, DATA
.data:00000048 ; ORG 0x48
.data:00000048 EXPORT x
.data:00000048 x DCD 0xA ; DATA XREF: main+8
.data:00000048 ; main+10
.data:00000048 ; .data ends
那么,现在x变量以某种方式变为全局的,现在被放置在另一个部分中。命名为data块(.data)。有人可能会问,为什么文本字符串被放在了代码块(.text),而且x可以被放在这?因为这是变量,而且根据它的定义,它可以变化,也有可能会频繁变化,不频繁变化的代码块可以被放置在ROM中,变化的变量在RAM中,当有ROM时在RAM中储存不变的变量是不利于节约资源的。
此外,RAM中数据部分常量必须在之前初始化,因为在RAM使用后,很明显,将会包含杂乱的信息。
继续向前,我们可以看到,在代码片段,有个指针指向X变量(0ff_2C)。然后所有关于变量的操作都是通过这个指针。这也是x变量可以被放在远离这里地方的原因。所以他的地址一定被存在离这很近的地方。LDR指令在thumb模式下只可访问指向地址在1020bytes内的数据。同样的指令在ARM模式下——范围就达到了4095bytes,也就是x变量地址一定要在这附近的原因。因为没法保证链接时会把这个变量放在附近。
另外,如果变量以const声明,Keil编译环境下则会将变量放在.constdata部分,大概从那以后,链接时就可以把这部分和代码块放在ROM里了。
6.6 scanf()结果检查
正如我之前所见的,现在使用scanf()有点过时了,但是如过我们不得不这样做时,我们需要检查scanf()执行完毕时是否发生了错误。
#include <stdio.h>
int main()
{
int x;
printf ("Enter X:
");
if (scanf ("%d", &x)==1)
printf ("You entered %d...
", x);
else
printf ("What you entered? Huh?
");
return 0;
};
按标准,scanf()函数返回成功获取的字段数。
在我们的例子中,如果事情顺利,用户输入一个数字,scanf()将会返回1或0或者错误情况下返回EOF.
这里,我们添加了一些检查scanf()结果的c代码,用来打印错误信息:
按照预期的回显:
C:...>ex3.exe
Enter X:
123
You entered 123...
C:...>ex3.exe
Enter X:
ouch
What you entered? Huh?
6.6.1 MSVC: x86
我们可以得到这样的汇编代码(msvc2010):
lea eax, DWORD PTR _x$[ebp]
push eax
push OFFSET $SG3833 ; ’%d’, 00H
call _scanf
add esp, 8
cmp eax, 1
jne SHORT $LN2@main
mov ecx, DWORD PTR _x$[ebp]
push ecx
push OFFSET $SG3834 ; ’You entered %d...’, 0aH, 00H
call _printf
add esp, 8
jmp SHORT $LN1@main
$LN2@main:
push OFFSET $SG3836 ; ’What you entered? Huh?’, 0aH, 00H
call _printf
add esp, 4
$LN1@main:
xor eax, eax
调用函数(main())必须能够访问到被调用函数(scanf())的结果,所以callee把这个值留在了EAX寄存器中。
然后我们在"CMP EAX, 1"指令的帮助下,换句话说,我们将eax中的值与1进行比较。
JNE根据CMP的结果判断跳至哪,JNE表示(jump if Not Equal)
所以,如果EAX中的值不等于1,那么处理器就会将执行流程跳转到JNE指向的,在我们的例子中是$LN2@main,当流程跳到这里时,CPU将会带着参数"What you entered? Huh?"执行printf(),但是执行正常,就不会发生跳转,然后另外一个printf()就会执行,两个参数为"You entered %d…"及x变量的值。
因为第二个printf()并没有被执行,后面有一个JMP(无条件跳转),就会将执行流程到第二个printf()后"XOR EAX, EAX"前,执行完返回0。
那么,可以这么说,比较两个值通常使用CMP/Jcc这对指令,cc是条件码,CMP比较两个值,然后设置processor flag,Jcc检查flags然后判断是否跳。
但是事实上,这却被认为是诡异的。但是CMP指令事实上,但是CMP指令实际上是SUB(subtract),所有算术指令都会设置processor flags,不仅仅只有CMP,当我们比较1和1时,1结果就变成了0,ZF flag就会被设定(表示最后一次的比较结果为0),除了两个数相等以外,再没有其他情况了。JNE 检查ZF flag,如果没有设定就会跳转。JNE实际上就是JNZ(Jump if Not Zero)指令。JNE和JNZ的机器码都是一样的。所以CMP指令可以被SUB指令代替,几乎一切的都没什么变化。但是SUB会改变第一个数,CMP是"SUB without saving result".
6.6.2 MSVC: x86:IDA
现在是时候打开IDA然后尝试做些什么了,顺便说一句。对于初学者来说使用在MSVC中使用/MD是个非常好的主意。这样所有独立的函数不会从可执行文件中link,而是从MSVCR*.dll。因此这样可以简单明了的发现函数在哪里被调用。
当在IDA中分析代码时,建议一定要做笔记。比如在分析这个例子的时候,我们看到了JNZ将要被设置为error,所以点击标注,然后标注为"error"。另外一处标注在"exit":
.text:00401000 _main proc near
.text:00401000
.text:00401000 var_4 = dword ptr -4
.text:00401000 argc = dword ptr 8
.text:00401000 argv = dword ptr 0Ch
.text:00401000 envp = dword ptr 10h
.text:00401000
.text:00401000 push ebp
.text:00401001 mov ebp, esp
.text:00401003 push ecx
.text:00401004 push offset Format ; "Enter X:
"
.text:00401009 call ds:printf
.text:0040100F add esp, 4
.text:00401012 lea eax, [ebp+var_4]
.text:00401015 push eax
.text:00401016 push offset aD ; "%d"
.text:0040101B call ds:scanf
.text:00401021 add esp, 8
.text:00401024 cmp eax, 1
.text:00401027 jnz short error
.text:00401029 mov ecx, [ebp+var_4]
.text:0040102C push ecx
.text:0040102D push offset aYou ; "You entered %d...
"
.text:00401032 call ds:printf
.text:00401038 add esp, 8
.text:0040103B jmp short exit
.text:0040103D ; ---------------------------------------------------------------------------
.text:0040103D
.text:0040103D error: ; CODE XREF: _main+27
.text:0040103D push offset aWhat ; "What you entered? Huh?
"
.text:00401042 call ds:printf
.text:00401048 add esp, 4
.text:0040104B
.text:0040104B exit: ; CODE XREF: _main+3B
.text:0040104B xor eax, eax
.text:0040104D mov esp, ebp
.text:0040104F pop ebp
.text:00401050 retn
.text:00401050 _main endp
现在理解代码就变得非常简单了。然而过分的标注指令却不是一个好主意。
函数的一部分有可能也会被IDA隐藏:
我隐藏了两部分然后分别给它们命名:
.text:00401000 _text segment para public ’CODE’ use32
.text:00401000 assume cs:_text
.text:00401000 ;org 401000h
.text:00401000 ; ask for X
.text:00401012 ; get X
.text:00401024 cmp eax, 1
.text:00401027 jnz short error
.text:00401029 ; print result
.text:0040103B jmp short exit
.text:0040103D ; ---------------------------------------------------------------------------
.text:0040103D
.text:0040103D error: ; CODE XREF: _main+27
.text:0040103D push offset aWhat ; "What you entered? Huh?
"
.text:00401042 call ds:printf
.text:00401048 add esp, 4
.text:0040104B
.text:0040104B exit: ; CODE XREF: _main+3B
.text:0040104B xor eax, eax
.text:0040104D mov esp, ebp
.text:0040104F pop ebp
.text:00401050 retn
.text:00401050 _main endp
如果要显示这些隐藏的部分,我们可以点击数字上的+。
为了压缩"空间",我们可以看到IDA怎样用图表代替一个函数的(见图6.7),然后在每个条件跳转处有两个箭头,绿色和红色。绿色箭头代表如果跳转触发的方向,红色则相反。
当然可以折叠节点,然后备注名称,我像这样处理了3块(见图 6.8):
这个非常的有用。可以这么说,逆向工程师很重要的一点就是缩小他所有的信息。

图6.7: IDA 图形模式
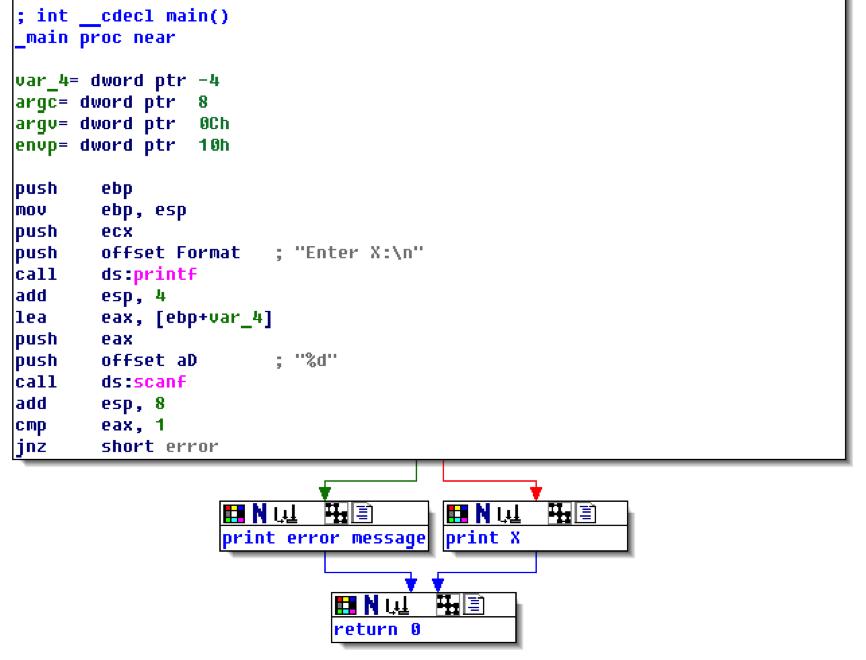
图6.8: Graph mode in IDA with 3 nodes folded
6.6.3 MSVC: x86 + OllyDbg
让我们继续在OllyDbg中看这个范例程序,使它认为scanf()怎么运行都不会出错。
当本地变量地址被传递给scanf()时,这个变量还有一些垃圾数据。这里是0x4CD478:见图6.10
当scanf()执行时,我在命令行窗口输入了一些不是数字的东西,像"asdasd".scanf()结束后eax变为了0.也就意味着有错误发生:见图6.11
我们也可以发现栈中的本地变量并没有发生变化,scanf()会在那里写入什么呢?其实什么都没有,只是返回了0.
现在让我们尝试修改这个程序,右击EAX,在选项中有个"set to 1",这正是我们所需要的。
现在EAX是1了。那么接下来的检查就会按照我们的需求执行,然后printf()将会打印出栈上的变量。
按下F9我们可以在窗口中看到:
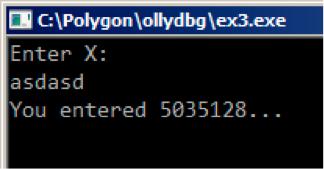
图6.9
实际上,5035128是栈上一个数据(0x4CD478)的十进制表示!

图6.10
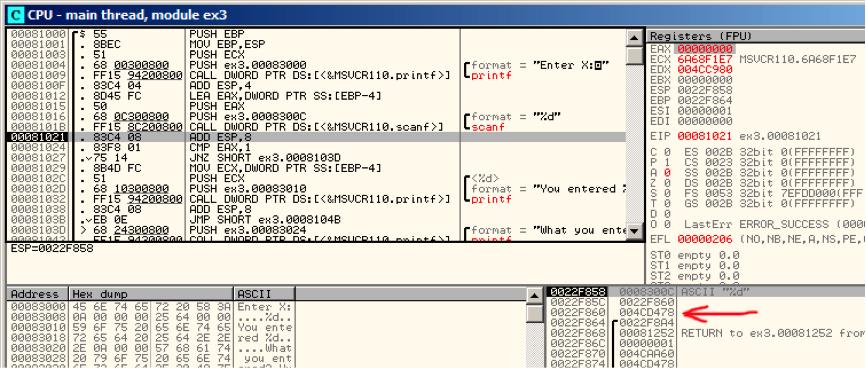
图6.11
6.6.4 MSVC: x86 + Hlew
这也是一个关于可执行文件patch的简单例子,我们之前尝试patch程序,所以程序总是打印数字,不管我们输入什么。
假设编译时并没有使用/MD,我们可以在.text开始的地方找到main()函数,现在让我们在Hiew中打开执行文件。找到.text的开始处(enter,F8,F6,enter,enter)
我们可以看到这个:表6.13
然后按下F9(update),现在文件保存在了磁盘中,就像我们想要的。
两个NOP可能看起来并不是那么完美,另一个方法是把0写在第二处(jump offset),所以JNZ就可以总是跳到下一个指令了。
另外我们也可以这样做:替换第一个字节为EB,这样就不修改第二处(jump offset),这样就会无条件跳转,不管我们输入什么,错误信息都可以打印出来了。
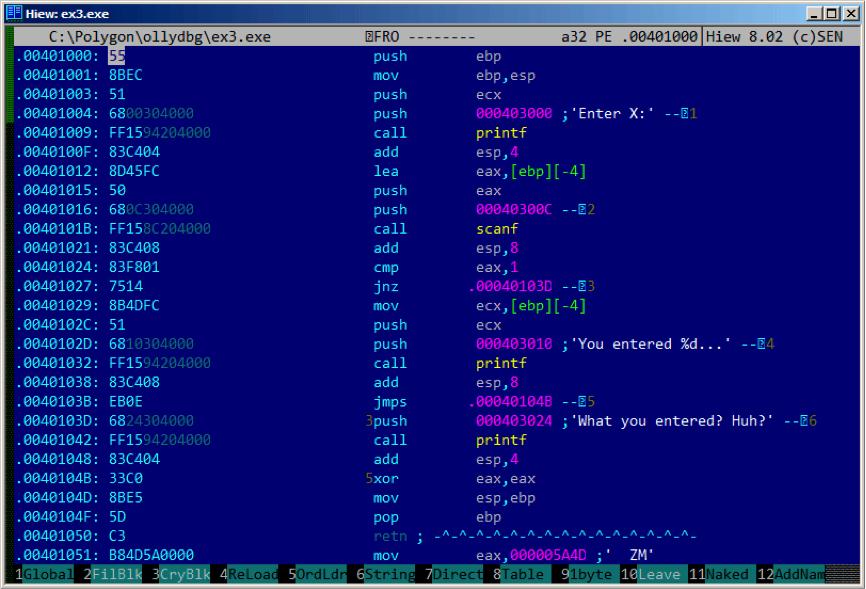
图6.12:main()函数

图6.13:Hiew 用两个NOP替换JNZ
6.6.5 GCC: x86
生成的代码和gcc 4.4.1是一样的,除了我们之前已经考虑过的
6.6.6 MSVC: x64
因为我们这里处理的是无整型变量。在x86-64中还是32bit,我们可以看出32bit的寄存器(前缀为E)在这种情况下是怎样使用的,然而64bit的寄存也有被使用(前缀R)
_DATA SEGMENT
$SG2924 DB ’Enter X:’, 0aH, 00H
$SG2926 DB ’%d’, 00H
$SG2927 DB ’You entered %d...’, 0aH, 00H
$SG2929 DB ’What you entered? Huh?’, 0aH, 00H
_DATA ENDS
_TEXT SEGMENT
x$ = 32
main PROC
$LN5:
sub rsp, 56
lea rcx, OFFSET FLAT:$SG2924 ; ’Enter X:’
call printf
lea rdx, QWORD PTR x$[rsp]
lea rcx, OFFSET FLAT:$SG2926 ; ’%d’
call scanf
cmp eax, 1
jne SHORT $LN2@main
mov edx, DWORD PTR x$[rsp]
lea rcx, OFFSET FLAT:$SG2927 ; ’You entered %d...’
call printf
jmp SHORT $LN1@main
$LN2@main:
lea rcx, OFFSET FLAT:$SG2929 ; ’What you entered? Huh?’
call printf
$LN1@main:
; return 0
xor eax, eax
add rsp, 56
ret 0
main ENDP
_TEXT ENDS
END
6.6.7 ARM:Optimizing Keil + thumb mode
var_8 = -8
PUSH {R3,LR}
ADR R0, aEnterX ; "Enter X:
"
BL __2printf
MOV R1, SP
ADR R0, aD ; "%d"
BL __0scanf
CMP R0, #1
BEQ loc_1E
ADR R0, aWhatYouEntered ; "What you entered? Huh?
"
BL __2printf
loc_1A ; CODE XREF: main+26
MOVS R0, #0
POP {R3,PC}
loc_1E ; CODE XREF: main+12
LDR R1, [SP,#8+var_8]
ADR R0, aYouEnteredD___ ; "You entered %d...
"
BL __2printf
B loc_1A
这里有两个新指令CMP 和BEQ.
CMP和x86指令中的相似,它会用一个参数减去另外一个参数然后保存flag.
BEQ是跳向另一处地址,如果数相等就会跳,如果最后一次比较结果为0,或者Z flag是1。和x86中的JZ是一样的。
其他的都很简单,执行流程分为两个方向,当R0被写入0后,两个方向则会合并,作为函数的返回值,然后函数结束。