0x00 写在前面
第一次在WooYun发文章,不知道是否符合众客官口味,望轻拍。
这篇文章翻译至我的这篇博客,主要介绍了一种叫做BROP的攻击,该文章主要介绍原理部分,对该攻击的重现可以参看我的另外一篇博客。
BROP攻击基于一篇发表在Oakland 2014的论文Hacking Blind,作者是来自Standford的Andrea Bittau,以下是相关paper和slide的链接:
以及BROP的原网站地址:
Blind Return Oriented Programming (BROP) Website
可以说这篇论文是今年看过的最让我感到兴奋的论文(没有之一),如果要用一个词来形容它的话,那就只有“不能更帅”才能表达我对它的喜爱程度了!
这篇文章假设读者已经了解Return-Oriented Programming (ROP) 的基本概念,所以只是介绍BROP的实现原理,如果还不清楚什么是ROP,请先出门左转,看看Wiki的相关介绍。
BROP的实现真的是让人感到非常“cool”和“smart”,我希望能够通过这篇文章把它讲清楚。
0x01 BROP攻击的目标和前提条件
目标:通过ROP的方法远程攻击某个应用程序,劫持该应用程序的控制流。我们可以不需要知道该应用程序的源代码或者任何二进制代码,该应用程序可以被现有的一些保护机制如NX, ASLR, PIE, 以及stack canaries等保护,应用程序所在的服务器可以是32位系统或者64位系统。
初看这个目标感觉实现起来特别困难。其实这个攻击有两个前提条件的:
- 必须先存在一个已知的stack overflow的漏洞,而且攻击者知道如何触发这个漏洞;
- 服务器进程在crash之后会重新复活,并且复活的进程不会被re-rand(意味着虽然有ASLR的保护,但是复活的进程和之前的进程的地址随机化是一样的)。这个需求其实是合理的,因为当前像nginx, MySQL, Apache, OpenSSH, Samba等服务器应用都是符合这种特性的。
0x10 BROP的攻击流程 1 - 远程dump内存
由于我们不知道被攻击程序的内存布局,所以首先要做的事情就是通过某种方法从远程服务器dump出该程序的内存到本地,为了做到这点我们需要调用一个系统调用write,传入一个socket文件描述符,如下所示:
write(int sock, void *buf, int len)
将这条系统调用转换成4条汇编指令,如图所示:
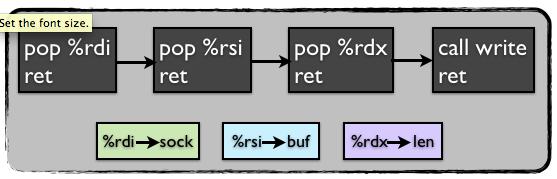
所以从ROP攻击的角度来看,我们只需要找到四个相应的gadget,然后在栈上构造好这4个gadget的内存地址,依次进行顺序调用就可以了。
但是问题是我们现在连内存分布都不知道,该如何在内存中找到这4个gadgets呢?特别是当系统部署了ASLR和stack canaries等保护机制,似乎这件事就更难了。
所以我们先将这个问题放一放,在脑袋里记着这个目标,先来做一些准备工作。
攻破Stack Canaries防护
如果不知道什么是stack canaries可以先看这里,简单来说就是在栈上的return address下面放一个随机生成的数(成为canary),在函数返回时进行检查,如果发现这个canary被修改了(可能是攻击者通过buffer overflow等攻击方法覆盖了),那么就报错。
那么如何攻破这层防护呢?一种方法是brute-force暴力破解,但这个很低效,这里作者提出了一种叫做“stack reading”的方法:
假设这是我们想要overflow的栈的布局:

我们可以尝试任意多次来判断出overflow的长度(直到进程由于canary被破坏crash了,在这里即为4096+8=4104个字节),之后我们将这4096个字节填上任意值,然后一个一个字节顺序地进行尝试来还原出真实的canary,比如说,我们将第4097个字节填为x,如果x和原来的canary中的第一个字节是一样的话,那么进程不会crash,否则我们尝试下一个x的可能性,在这里,由于一个字节只有256种可能,所以我们只要最多尝试256次就可以找到canary的某个正确的字节,直到我们得到8个完整的canary字节,该流程如下图所示:
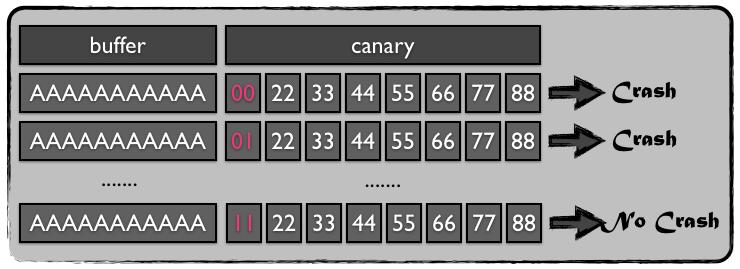
我们同样可以用这种方法来得到保存好的frame pointer和return address。
寻找stop gadget
到目前为止,我们已经得到了合适的canary来绕开stack canary的保护, 接下来的目标就是找到之前提到的4个gadgets。
在寻找这些特定的gadgets之前,我们需要先来介绍一种特殊的gadget类型:stop gadget.
一般情况下,如果我们把栈上的return address覆盖成某些我们随意选取的内存地址的话,程序有很大可能性会挂掉(比如,该return address指向了一段代码区域,里面会有一些对空指针的访问造成程序crash,从而使得攻击者的连接(connection)被关闭)。但是,存在另外一种情况,即该return address指向了一块代码区域,当程序的执行流跳到那段区域之后,程序并不会crash,而是进入了无限循环,这时程序仅仅是hang在了那里,攻击者能够一直保持连接状态。于是,我们把这种类型的gadget,成为stop gadget,这种gadget对于寻找其他gadgets取到了至关重要的作用。
寻找可利用的(potentially useful)gadgets
假设现在我们找到了某个可以造成程序block住的stop gadget,比如一个无限循环,或者某个blocking的系统调用(sleep),那么我们该如何找到其他useful gadgets呢?(这里的“useful”是指有某些功能的gadget,而不是会造成crash的gadget)。
到目前为止我们还是只能对栈进行操作,而且只能通过覆盖return address来进行后续的操作。假设现在我们猜到某个useful gadget,比如pop rdi; ret, 但是由于在执行完这个gadget之后进程还会跳到栈上的下一个地址,如果该地址是一个非法地址,那么进程最后还是会crash,在这个过程中攻击者其实并不知道这个useful gadget被执行过了(因为在攻击者看来最后的效果都是进程crash了),因此攻击者就会认为在这个过程中并没有执行到任何的useful gadget,从而放弃它,这个步骤如下图所示:

但是,如果我们有了stop gadget,那么整个过程将会很不一样. 如果我们在需要尝试的return address之后填上了足够多的stop gadgets,如下图所示:
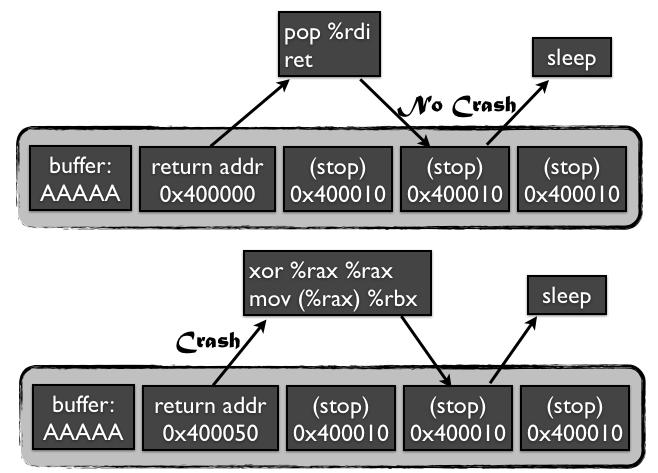
那么任何会造成进程crash的gadget最后还是会造成进程crash,而那些useful gadget则会进入block状态。尽管如此,还是有一种特殊情况,即那个我们需要尝试的gadget也是一个stop gadget,那么如上所述,它也会被我们标识为useful gadget。不过这并没有关系,因为之后我们还是需要检查该useful gadget是否是我们想要的gadget.
最后一步:远程dump内存
到目前为止,似乎准备工作都做好了,我们已经可以绕过canary防护,并且得到很多不会造成进程crash的“potential useful gadget”了,那么接下来就是该如何找到我们之前所提到的那四个gadgets呢?

如上图所示,为了找到前两个gadgets:pop %rsi; ret和pop %rdi; ret,我们只需要找到一种所谓的BROP gadget就可以了,这种gadget很常见,它做的事情就是恢复那些callee saved registers. 而对它进行一个偏移就能够生成pop %rdi和pop %rsi这两个gadgets.
不幸的是pop %rdx; ret这个gadget并不容易找到,它很少出现在代码里, 所以作者提出一种方法,相比于寻找pop %rdx指令,他认为可以利用strcmp这个函数调用,该函数调用会把字符串的长度赋值给%rdx,从而达到相同的效果。另外strcmp和write调用都可以在程序的Procedure Linking Table (PLT)里面找到.
所以接下来的任务就是:
- 找到所谓的
BROP Gadget; - 找到对应的PLT项。
寻找BROP Gadget
事实上BROP gadgets特别特殊,因为它需要顺序地从栈上pop6个值然后执行ret。所以如果我们利用之前提到的stop gadget的方法就可以很容易找到这种特殊的gadget了,我们只需要在stop gadget之前填上6个会造成crash的地址:
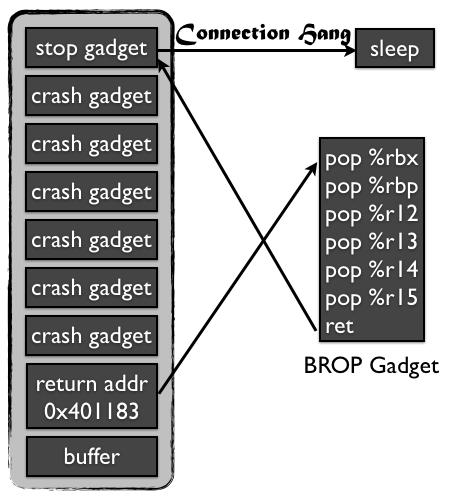
如果任何useful gadget满足这个条件且不会crash的话,那么它基本上就是BROP gadgets了。
寻找PLT项
PLT是一个跳转表,它的位置一般在可执行程序开始的地方,该机制主要被用来给应用程序调用外部函数(比如libc等),具体的细节可以看相关的Wiki。它有一个非常独特的signature:每一个项都是16个字节对齐,其中第0个字节开始的地址指向改项对应函数的fast path,而第6个字节开始的地址指向了该项对应函数的slow path:

另外,大部分的PLT项都不会因为传进来的参数的原因crash,因为它们很多都是系统调用,都会对参数进行检查,如果有错误会返回EFAULT而已,并不会造成进程crash。所以攻击者可以通过下面这个方法找到PLT:如果攻击者发现好多条连续的16个字节对齐的地址都不会造成进程crash,而且这些地址加6得到的地址也不会造成进程crash,那么很有可能这就是某个PLT对应的项了。
那么当我们得到某个PLT项,我们该如何判断它是否是strcmp或者write呢?
对于strcmp来说, 作者提出的方法是对其传入不同的参数组合,通过该方法调用返回的结果来进行判断。由于BROP gadget的存在,我们可以很方便地控制前两个参数,strcmp会发生如下的可能性:
arg1 | arg2 | result
:--: | :--: | :--:
readable | 0x0 | crash
0x0 | readable | crash
0x0 | 0x0 | crash
readable | readable | nocrash
根据这个signature, 我们能够在很大可能性上找到strcmp对应的PLT项。
而对于write调用,虽然它没有这种类似的signature,但是我们可以通过检查所有的PLT项,然后触发其向某个socket写数据来检查write是否被调用了,如果write被调用了,那么我们就可以在本地看到传过来的内容了。
最后一步就是如何确定传给write的socket文件描述符是多少了。这里有两种办法:1. 同时调用好几次write,把它们串起来,然后传入不同的文件描述符数;2. 同时打开多个连接,然后使用一个相对较大的文件描述符数字,增加匹配的可能性。
到这一步为止,攻击者就能够将整个.text段从内存中通过socket写到本地来了,然后就可以对其进行反编译,找到其他更多的gadgets,同时,攻击者还可以dump那些symbol table之类的信息,找到PLT中其它对应的函数项如dup2和execve等。
0x11 BROP的攻击流程 2 - 实施攻击
到目前为止,最具挑战性的部分已经被解决了,我们已经可以得到被攻击进程的整个内存空间了,接下来就是按部就班了(从论文中翻译):
- 将socket重定向到标准输入/输出(standard input/output)。攻击者可以使用
dup2或close,跟上dup或者fcntl(F_DUPFD)。这些一般都能在PLT里面找到。 - 在内存中找到
/bin/sh。其中一个有效的方法是从symbol table里面找到一个可写区域(writable memory region),比如environ,然后通过socket将/bin/sh从攻击者这里读过去。 -
execveshell. 如果execve不在PLT上, 那么攻击者就需要通过更多次的尝试来找到一个pop rax; ret和syscall的gadget.
归纳起来,BROP攻击的整个步骤是这样的:
- 通过一个已知的stack overflow的漏洞,并通过stack reading的方式绕过stack canary的防护,试出某个可用的return address;
- 寻找
stop gadget:一般情况下这会是一个在PLT中的blocking系统调用的地址(sleep等),在这一步中,攻击者也可以找到PLT的合法项; - 寻找
BROP gadget:这一步之后攻击者就能够控制write系统调用的前两个参数了; - 通过signature的方式寻找到PLT上的
strcmp项,然后通过控制字符串的长度来给%rdx赋值,这一步之后攻击者就能够控制write系统调用的第三个参数了; - 寻找PLT中的
write项:这一步之后攻击者就能够将整个内存从远端dump到本地,用于寻找更多的gadgets; - 有了以上的信息之后,就可以创建一个shellcode来实施攻击了。
0x100 后记
以上就是BROP攻击的原理,在这篇博文中重现了这个攻击,有兴趣的可以去看看。
其实在整个攻击过程中最酷的要数第一个步骤:如何dump内存,之后的步骤其实就是传统的ROP攻击了。明白了原理之后,其实最好的了解该攻击的方法就是看源代码了,这个对了解整个ROP会有非常大的帮助。